Redis TimeSeries 2 使用
概要: 学习使用Redis的时序数据类型 Redis Time Series
创建时间: 2022.11.01 23:04:48
更新时间: 2023.08.16 22:25:34
写在前面
如何快速熟悉Redis TimeSeries
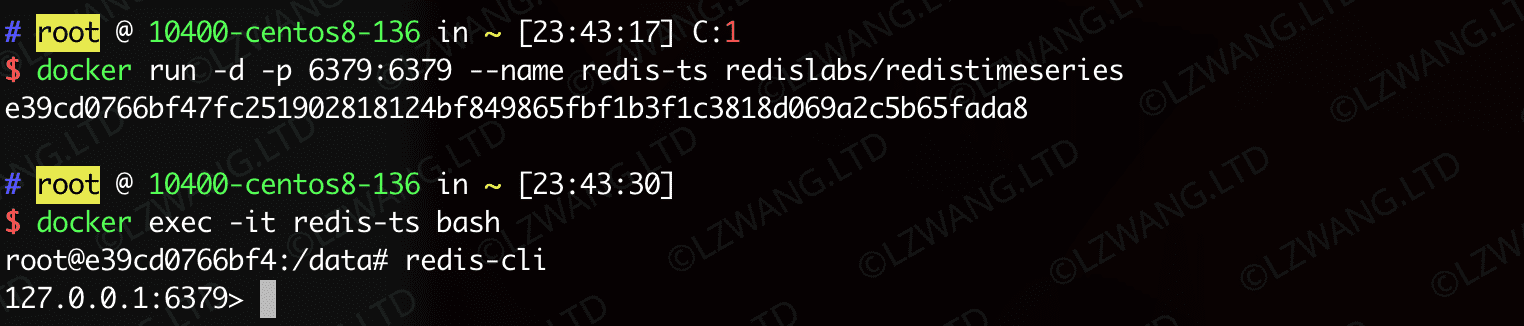
推荐使用Docker形式启动,方便快捷
| Bash |
|---|
| docker run -d -p 6379:6379 --name redis-ts redislabs/redistimeseries
|
redis-cli 交互式终端
| Bash |
|---|
| docker exec -it redis-ts redis-cli
|
接着就可以实践下面的各种操作
如何清理测试的Redis环境
最后如果需求删除容器清理环境,在宿主机环境上执行如下命令即可
基本命令
TS.CREATE 创建TS数据
作用:创建新的TS数据,时间复杂度 O(1)
| Bash |
|---|
| TS.CREATE key
[RETENTION retentionPeriod]
[ENCODING [UNCOMPRESSED|COMPRESSED]]
[CHUNK_SIZE size]
[DUPLICATE_POLICY policy]
[LABELS {label value}...]
|
RETENTION 数据超期时间,当TS数据量超过此值时,旧的数据将无法获取,默认值为0,即数据永不超期ENCODING 是否启用压缩,根据Redis官方说明,启用压缩后即可以降低大概90%的内存占用,也可以提升内存性能,默认启用CHUNK_SIZE 每个块的字节数大小,必须为8的整数倍,数值范围 [48...1048576] ,默认值 4096 字节(注意,使用 TS.ALTER 命令更改TS数据配置时,不会更改已有的块大小)DUPLICATE_POLICY 处理具有完全一样时间戳的多个TS数据样本的策略,分为以下几种:a)BLOCK 提示时间戳相同而报错(默认策略);b)FIRST 保留第一次的;c)LAST 保留最后一次的;d)MIN 保留最小的;e)MAX 保留最大的;f)SUM 保留所有值的和LABELS 用来表示当前TS数据的元信息,属于哪一个标签label下的什么值value(支持多个标签),其作用在于后面使用到操作多个TS数据的命令(如 TS.MGET , TS.MRANG, TS.MREVANGE)时,利用标签将它们聚合,实现单次操作多个TS数据
示例:创建温度TS数据 key=temperature:2:32,10个后自动超期,当有相同时间戳数据时取最大值,标记为 sensor_id=2 , area_id=32
| Bash |
|---|
| TS.CREATE temperature:2:32 RETENTION 100 DUPLICATE_POLICY MAX LABELS sensor_id 2 area_id 32
|
警告
如果存在相同 key 的TS数据,执行 TS.CREATE 命令时会报错

TS.ALTER 更新TS数据属性
复杂度取决于TS数据需要更新的关联标签数量N,复杂度为 O(N)
| Bash |
|---|
| TS.ALTER key
[RETENTION retentionPeriod]
[CHUNK_SIZE size]
[DUPLICATE_POLICY policy]
[LABELS [{label value}...]]
|
TS.CREATE 命令,示例
| Bash |
|---|
| TS.ALTER temperature:2:32 RETENTION 100 DUPLICATE_POLICY MAX LABELS sensor_id 2 area_id 32 sub_area_id 15
|
TS.ADD 新增一个样本数据
新增1个TS数据样本,在不使用规则前提下,复杂度 O(1)
| Bash |
|---|
| TS.ADD key timestamp value
[RETENTION retentionPeriod]
[ENCODING [COMPRESSED|UNCOMPRESSED]]
[CHUNK_SIZE size]
[ON_DUPLICATE policy]
[LABELS {label value}...]
|
key 为TS数据的键名,value 必须为数值,不大于 2^64 ,且不能是 NaN 或者 ∞ 这样的特殊值
提示
如果 key 在Redis中不存在,则会使用2~6行的参数自动创建,效果同 TS.CREATE
假定我们使用上一节已经创建的数据,为其增加样本,有两种方式
(1)自定义时间戳,使用Linux的时间戳格式(执行命令 date +%s 即可获取)
| Bash |
|---|
| TS.ADD temperature:2:32 1667318627 10
|
* 即可,精度到毫秒
| Bash |
|---|
| TS.ADD temperature:2:32 * 13
|

TS.GET 获取最新样本数据
获取最新的TS数据,复杂度 O(1)
如上面已经添加的数据,直接执行命令即可获取时间戳和数值
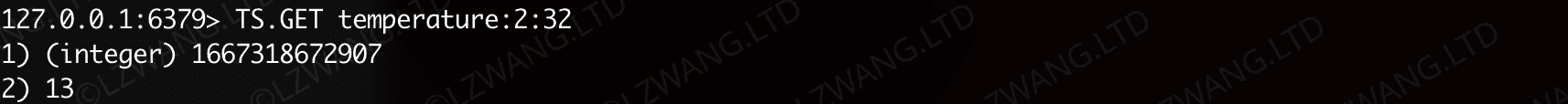
TS.DEL 删除一组样本数据
删除指定时间范围内的TS样本数据,假定有N个数据,那么命令的时间复杂度 O(N)
| Bash |
|---|
| TS.DEL key fromTimestamp toTimestamp
|
1667318627 到 1667318672907 之间的所有数据,包含端点值
| Bash |
|---|
| TS.DEL temperature:2:32 1667318627 1667318672907
|

TS.INFO 获取TS数据信息
直接返回指定TS数据的统计详情信息,复杂度 O(1)
示例如下
| Bash |
|---|
| TS.ADD temperature:2:32 1667318627 10
TS.ADD temperature:2:32 1667318630 12
TS.ADD temperature:2:32 1667318633 11
TS.ADD temperature:2:32 1667318636 15
TS.INFO temperature:2:32
|
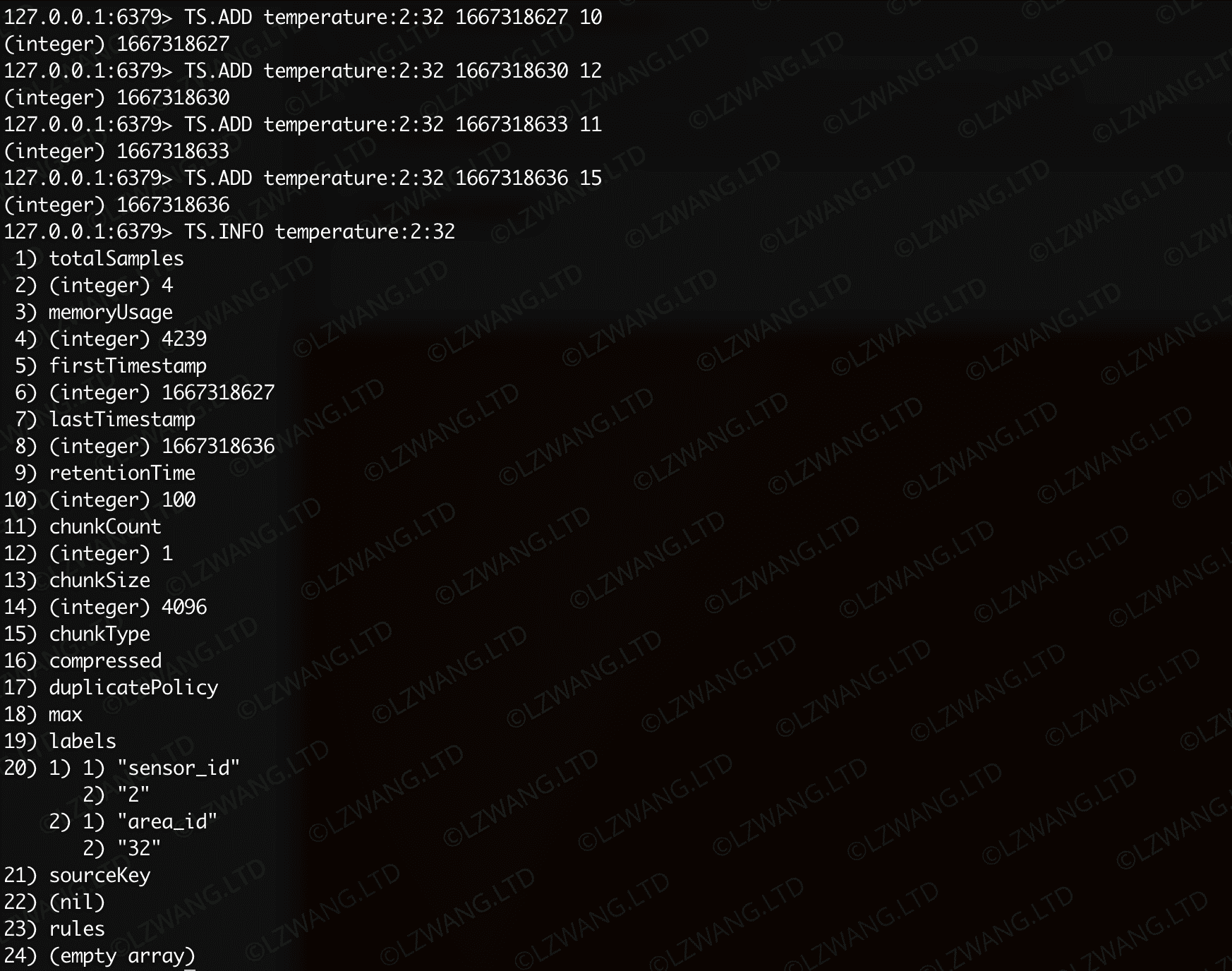
各个字段解释如下
| 字段 |
解释 |
| totalSamples |
此TS数据中的总样本数量 |
| memoryUsage |
内存占用大小(单位字节) |
| firstTimestamp |
最早的时间戳 |
| lastTimestamp |
最晚的时间戳 |
| retentionTime |
自动超期限制 |
| chunkCount |
已存储的样本占据了多少个块 |
| chunkSize |
每个存储块的大小(单位字节) |
| chunkType |
存储块类型(是否压缩) |
| duplicatePolicy |
相同时间戳数据处理策略 |
| labels |
关联的标签 |
| sourceKey |
规则关联的源键名(详见后面 TS.CREATERULE 和 TS.DELRULE) |
| rules |
规则(详见后面 TS.CREATERULE 和 TS.DELRULE) |
进阶命令
TS.CREATERULE 创建规则
创建两个TS数据之间的回归规则,复杂度 O(1)
| Bash |
|---|
| TS.CREATERULE sourceKey destKey
AGGREGATION aggregator bucketDuration
[alignTimestamp]
|
如何理解TS数据间的规则?
可以将两个TS数据,sourceKey 和 destKey 之间的规则视作一个回归函数aggregator,回归函数的周期为bucketDuration(单位ms)。在达到一个回归周期后,destKey数据会根据回归函数计算出一个数值并增加到其TS数据样本集中。
这样做的好处是可以对原有的高密度采样数据 sourceKey进行一定规则的上采样,实现不同时间尺度下对数据的洞察。
目前 aggregator 支持的函数/规则有下面几种
| 回归函数 |
解释(针对单个回归周期) |
avg |
均值 |
sum |
求和 |
min |
最小值 |
max |
最大值 |
range |
最大值和最小值的差值 |
count |
样本数量 |
first |
第一个时间戳对应样本值 |
last |
最后一个时间戳对应样本值 |
std.p |
总体标准差 |
std.s |
样本标准差 |
var.p |
总体方差 |
var.s |
样本方差 |
twa |
基于时间权重的均值(TS版本1.8后支持) |
示例,以10s为回归周期,创建一个基础TS数据和一个基于求和规则的TS数据
| Bash |
|---|
| TS.CREATE temp:TLV LABELS type temp location TLV
TS.CREATE tempSum:TLV LABELS type temp location TLV
TS.CREATERULE temp:TLV tempSum:TLV AGGREGATION sum 10000
TS.ADD temp:TLV * 1
TS.GET tempSum:TLV
TS.ADD temp:TLV * 2
TS.GET tempSum:TLV
TS.ADD temp:TLV * 3
TS.GET tempSum:TLV
TS.ADD temp:TLV * 4
TS.GET tempSum:TLV
TS.ADD temp:TLV * 5
TS.GET tempSum:TLV
TS.ADD temp:TLV * 6
TS.GET tempSum:TLV
TS.ADD temp:TLV * 7
TS.GET tempSum:TLV
TS.ADD temp:TLV * 8
TS.GET tempSum:TLV
TS.ADD temp:TLV * 9
TS.GET tempSum:TLV
TS.ADD temp:TLV * 10
TS.GET tempSum:TLV
TS.ADD temp:TLV * 10
TS.GET tempSum:TLV
|
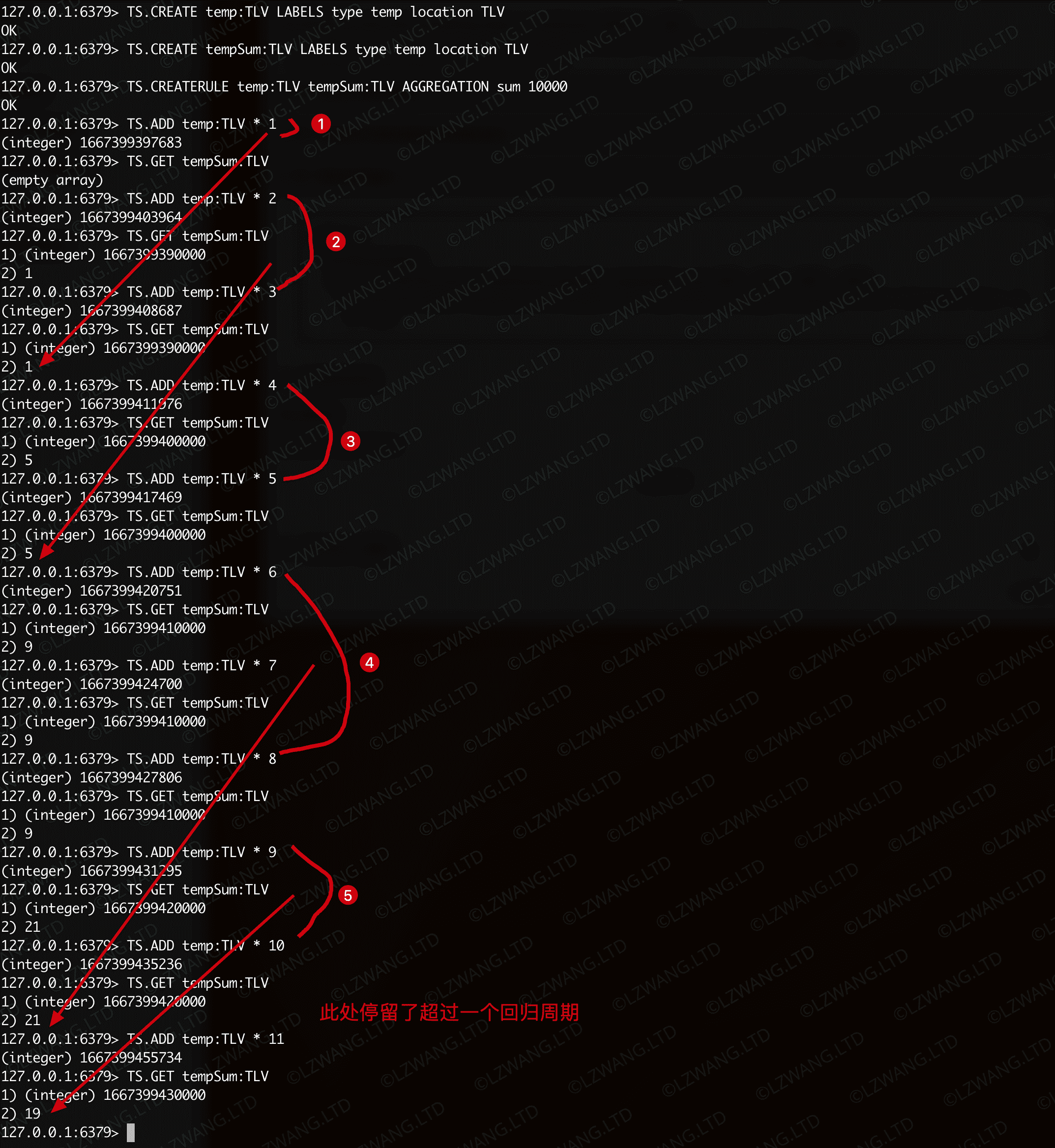
TS数据间的规则是如何生效的?
- 规则只针对创建规则后新增的数据有效
- 如果对
dstKey 数据手动添加数据(通过 TS.ADD , TS.MADD , TS.INCRBY 等命令),那么根据规则生成的样本数据会对手动添加的时间戳数据进行覆盖
- 如果在回归周期内
srcKey 没有新增数据,那么 dstKey 也不会产生数据
TS.DELRULE 删除规则
删除两个TS数据之间的关联规则,复杂度 O(1)
| Bash |
|---|
| TS.DELETERULE sourceKey destKey
|
提示
此操作仅移除两个TS之间的规则,不会删除数据
TS.INCRBY 增大指定样本数值
对TS数据采样数据进行增量更新,时间复杂度 O(1)(或 O(M) 当关联到M个规则时,需要更新M个TS数据)
| Bash |
|---|
| TS.INCRBY key value
[TIMESTAMP timestamp]
[RETENTION retentionPeriod]
[UNCOMPRESSED]
[CHUNK_SIZE size]
[LABELS {label value}...]
|
提示
- 在数据更新时,时间戳不能比TS数据上最新的时间戳旧
- 如果指定时间戳,那么必须不小于当前TS数据最新时间戳,此时会将增加后的数值赋给指定的新时间戳样本
- 如果指定的时间戳为当前最新的时间戳或更旧,那么会报错
- 如果未指定时间戳,被更新的样本数据默认采用服务器上最新的时间戳
- 后面3~6行是在
key 不存在时,自动创建TS数据的参数,参考 TS.CREATE
示例
| Bash |
|---|
| TS.CREATE myts
TS.ADD myts 1667403763000 50
TS.GET myts
TS.INCRBY myts 10 TIMESTAMP 1667403763000
TS.GET myts
TS.INCRBY myts 10 TIMESTAMP 1667403764000
TS.GET myts
TS.INCRBY myts 10
TS.GET myts
TS.INCRBY myts 10 TIMESTAMP 1667403845379
|

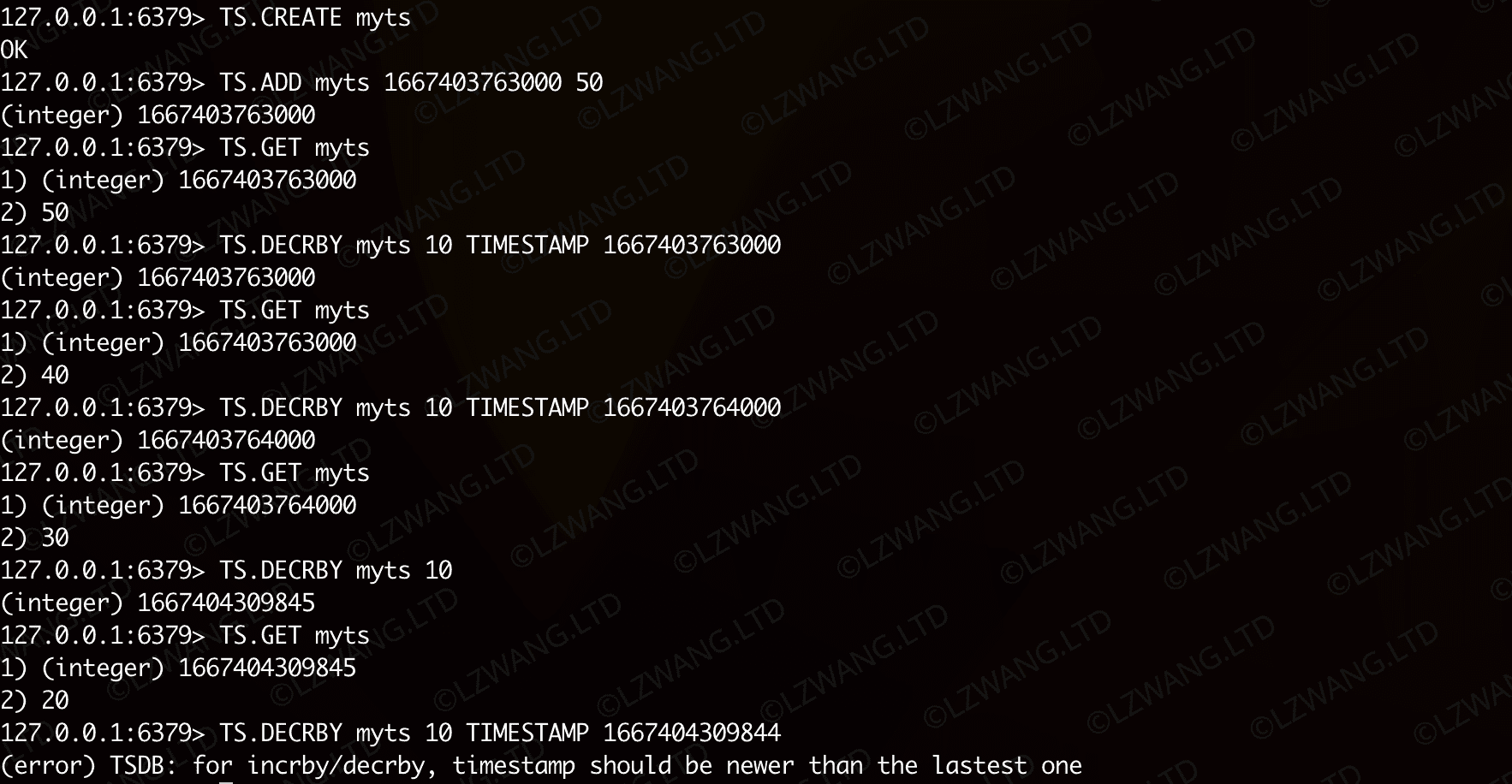
TS.DECRBY 减小指定样本数值
与 TS.INCRBY 命令类似,但是是对TS数据采样数据进行减量更新,时间复杂度 O(1)(或 O(M) 当关联到M个规则时,需要更新M个TS数据)
| Bash |
|---|
| TS.DECRBY key value
[TIMESTAMP timestamp]
[RETENTION retentionPeriod]
[UNCOMPRESSED]
[CHUNK_SIZE size]
[LABELS {label value}...]
|
| Bash |
|---|
| TS.CREATE myts
TS.ADD myts 1667403763000 50
TS.GET myts
TS.DECRBY myts 10 TIMESTAMP 1667403763000
TS.GET myts
TS.DECRBY myts 10 TIMESTAMP 1667403764000
TS.GET myts
TS.DECRBY myts 10
TS.GET myts
TS.DECRBY myts 10 TIMESTAMP 1667404309844
|
TS.QUERYINDEX 查询一组样本数据
找出所有符合 label 过滤条件的TS数据,假定找到了n个TS数据,那么复杂度为 O(n)
具体的过滤形式如下
| 过滤器 |
意义 |
label=value |
找出包含标签 label 且值为 value 的TS数据 |
label!=value |
找出包含标签 label 且值不为 value 的TS数据 |
label= |
找出不包含标签 label 的TS数据 |
label!= |
找出包含标签 label 的TS数据 |
label=(_value1_,_value2_,...) |
找出包含标签 label 且值为 value1 value2 之一的TS数据 |
label!=(value1,value2,...) |
找出包含标签 label 且值不为 value1 value2 任一个的TS数据 |
示例
| Bash |
|---|
| TS.CREATE myts-1 LABELS label-a x label-b 1
TS.CREATE myts-2 LABELS label-a x label-b 2
TS.CREATE myts-3 LABELS label-a x
TS.CREATE myts-4 LABELS label-a y
TS.CREATE myts-5 LABELS label-a y label-b 2
TS.QUERYINDEX label-a=x
TS.QUERYINDEX label-a=y
TS.QUERYINDEX label-a=(x,y)
TS.QUERYINDEX label-a=x label-b=
TS.QUERYINDEX label-a=x label-b!=
TS.QUERYINDEX label-a=x label-b=(1,2)
TS.QUERYINDEX label-a=x label-b!=(1,2)
TS.QUERYINDEX label-a=(x,y) label-b=(1,2)
TS.QUERYINDEX label-a=(x,y) label-b!=(1,2)
|


TS.MADD 新增一组样本数据
对已存在的TS数据,批量添加样本数据,复杂度 O(N*M) (其中 N 是需要被更新的TS样本数量,M 是TS数据规则映射后的TS数据,如果对源TS数据没有规则映射,那么复杂度简化为 O(N) )
| Bash |
|---|
| TS.MADD {key timestamp value}...
|
| Bash |
|---|
| TS.CREATE myts1
TS.CREATE myts2
TS.MADD myts1 1000 34 myts1 1001 36 myts1 1002 40 myts2 900 36 myts2 1000 50
|

TS.MGET 获取一组样本数据
获取满足指定过滤器的TS数据的最新样本,复杂度 O(n)(其中 n 是满足条件的TS数据个数)
| Bash |
|---|
| TS.MGET [LATEST] [WITHLABELS | SELECTED_LABELS label...] FILTER filter...
|
参数解释
LATEST 参数仅用于由规则生成的TS数据,作用是(1)给出最新的TS数据值(2)给出源TS数据的时间戳区间 [fromTImestamp, toTimestamp](TS版本1.8+)WITHLABELS 或者 SELECTED_LABELS 参数用于在获取结果时显示TS数据的标签信息,如果不指定,那么返回结果的第二个属性值为空FILTER filter...参数表示过滤器,详见 TS.QUERYINDEX
示例
| Bash |
|---|
| TS.CREATE myts-1 LABELS label-a a-x label-b b-x
TS.CREATE myts-2 LABELS label-a a-x label-b b-y
TS.MADD myts-1 1000 2 myts-1 1010 4 myts-1 1020 8 myts-1 1030 16
TS.MADD myts-2 1005 5 myts-2 1015 25 myts-2 1025 45 myts-2 1035 55
TS.MGET FILTER label-a=a-x
TS.MGET WITHLABELS FILTER label-a=a-x
TS.MGET SELECTED_LABELS label-b FILTER label-a=a-x
|

TS.RANGE 正向查询一组样本数据
通过条件过滤查询样本数据,查询出来的数据分为多个bucket,复杂度为 O(n/m+k)(其中 n 是 样本数量,m 是chunk块大小,k 是被查询范围内的样本数量)
关于复杂度的官方解释
TS.RANGE complexity can be improved in the future by using binary search to find the start of the range, which makes this O(Log(n/m)+k*m). But, because m is small, you can disregard it and look at the operation as O(Log(n)+k).
| Bash |
|---|
| TS.RANGE key fromTimestamp toTimestamp
[LATEST]
[FILTER_BY_TS ts...]
[FILTER_BY_VALUE min max]
[COUNT count]
[[ALIGN align] AGGREGATION aggregator bucketDuration [BUCKETTIMESTAMP bt] [EMPTY]]
|
参数解释
fromTimestamp参数表示查询的时间戳区间起始值,可以是具体数值,也可以为 - 来表示所有样本数据的最早时间戳toTimestamp 参数表示查询的时间戳区间终止值,可以是具体数值,也可以为 +来表示所有样本数据的最晚时间戳LATEST 参数仅用于由规则生成的TS数据,作用是(1)给出最新的TS数据值(2)给出源TS数据的时间戳区间 [fromTImestamp, toTimestamp](TS版本1.8+)FILTER_BY_TS ts...参数用于查询特定时间戳(可多个)的TS数据FILTER_BY_VALUE min max 参数用于限制TS数据的值区间(前后均为闭区间)COUNT count 参数用于限制符合条件的TS数据值的数量 countALIGN align 参数用于对齐TS数据的时间戳,可以使用具体的偏移量数值进行对齐,也可以使用 - 或 start 表示对时间戳区间起始值对齐,或者使用 + 或 end 表示对时间戳区间终止值对齐AGGREGATION aggregator bucketDuration 参数用于对查询的数据结果进行回归分析,利用回归函数 aggregator 在回归周期 bucketDuration 内对查询到的值进行回归(参考TS.CREATERULE)BUCKETTIMESTAMP bt参数控制bucket时间戳上报格式(TS版本1.8+)EMPTY 参数控制是否将回归函数应用于空的bucket(TS版本1.8+)
示例,首先创建TS数据,并添加一些样本
| Bash |
|---|
| TS.CREATE myts
TS.MADD myts 1000 34 myts 1010 36 myts 1020 40
TS.MADD myts 2000 75 myts 2010 78 myts 2020 85
TS.MADD myts 3000 59 myts 3010 63 myts 3020 75
|
1000 2010 3050 的样本
| Bash |
|---|
| TS.RANGE myts - + FILTER_BY_TS 1000 2010 3050
|
3050 的样本,因此并没有得到查询结果

查询2,找出样本值在 40 到 78 之间的样本
| Bash |
|---|
| TS.RANGE myts - + FILTER_BY_VALUE 40 78
|

查询3,同查询2,但限制为3个样本
| Bash |
|---|
| TS.RANGE myts - + FILTER_BY_VALUE 40 78 COUNT 3
|

查询4,同查询2,但需要以1000ms为回归周期,做均值回归计算
| Bash |
|---|
| TS.RANGE myts - + FILTER_BY_VALUE 40 78 AGGREGATION avg 1000
|

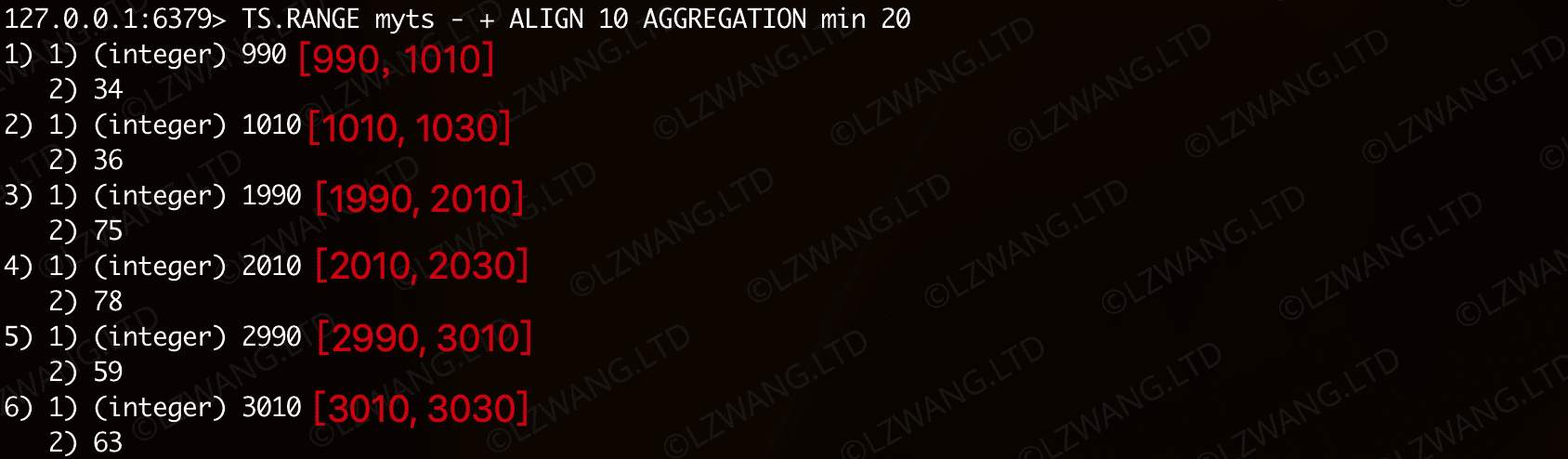
查询5,以10为偏移量对齐TS样本数据,并以20为周期做函数为最小值的回归计算
| Bash |
|---|
| TS.RANGE myts - + ALIGN 10 AGGREGATION min 20
|
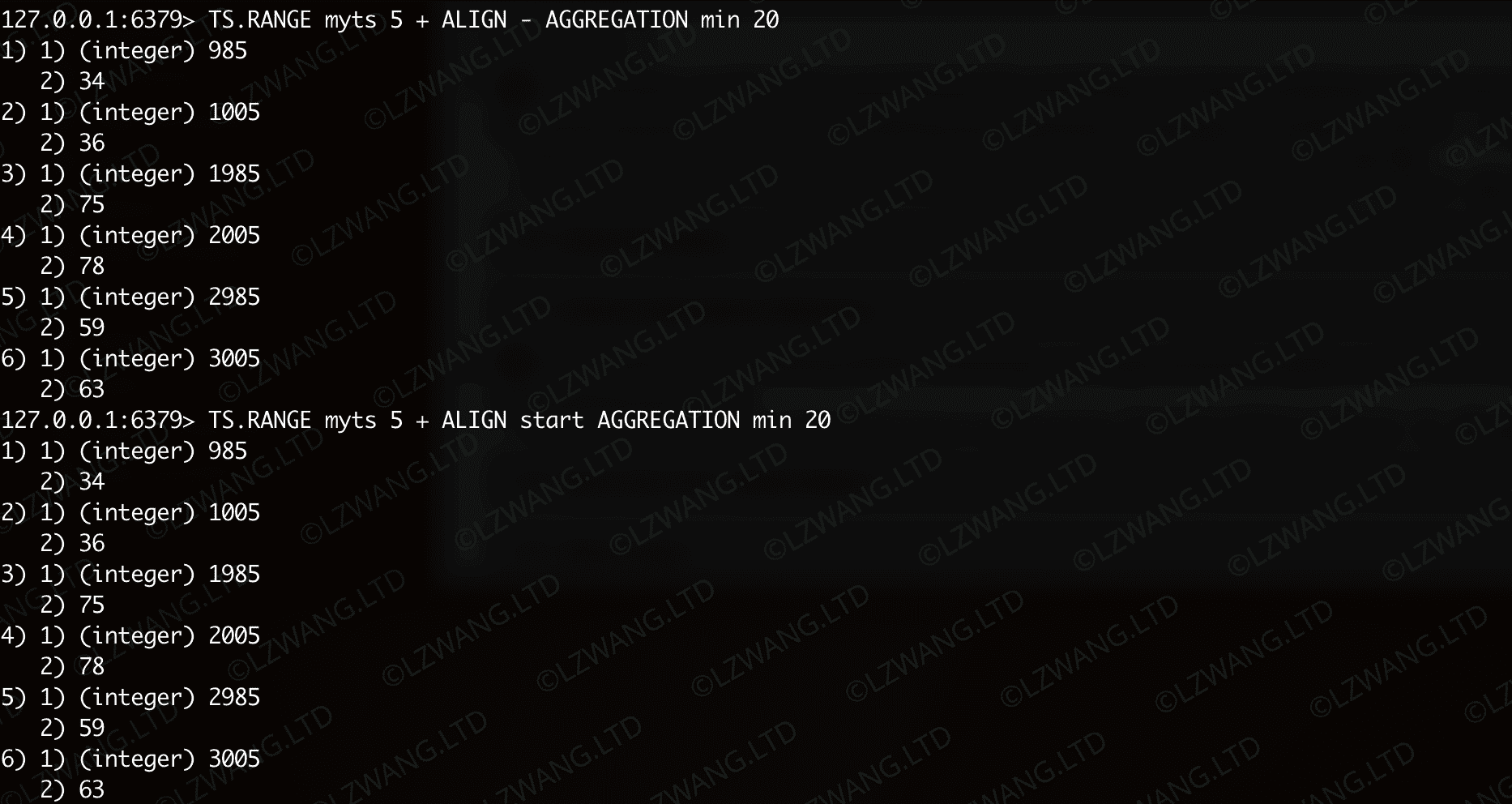
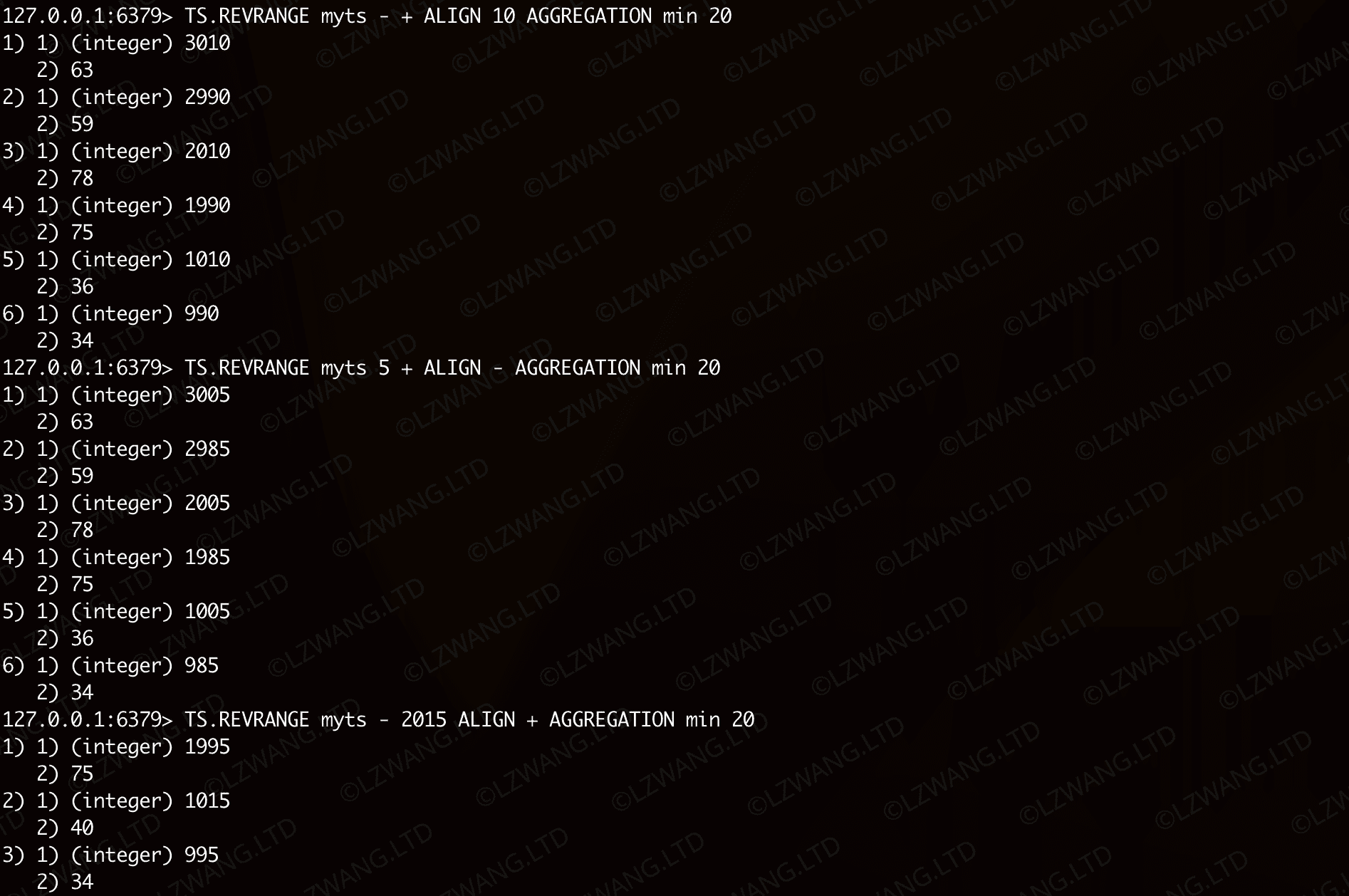
查询6,时间戳区间的起始值指定为 5 ,以起始值为偏移量对齐,并以20为周期做函数为最小值的回归计算
| Bash |
|---|
| TS.RANGE myts 5 + ALIGN - AGGREGATION min 20
TS.RANGE myts 5 + ALIGN start AGGREGATION min 20
|
查询7,时间戳区间的终止值指定为 2015 ,以终止值为偏移量对齐,并以20为周期做函数为最小值的回归计算
| Bash |
|---|
| TS.RANGE myts - 2015 ALIGN + AGGREGATION min 20
TS.RANGE myts - 2015 ALIGN end AGGREGATION min 20
|

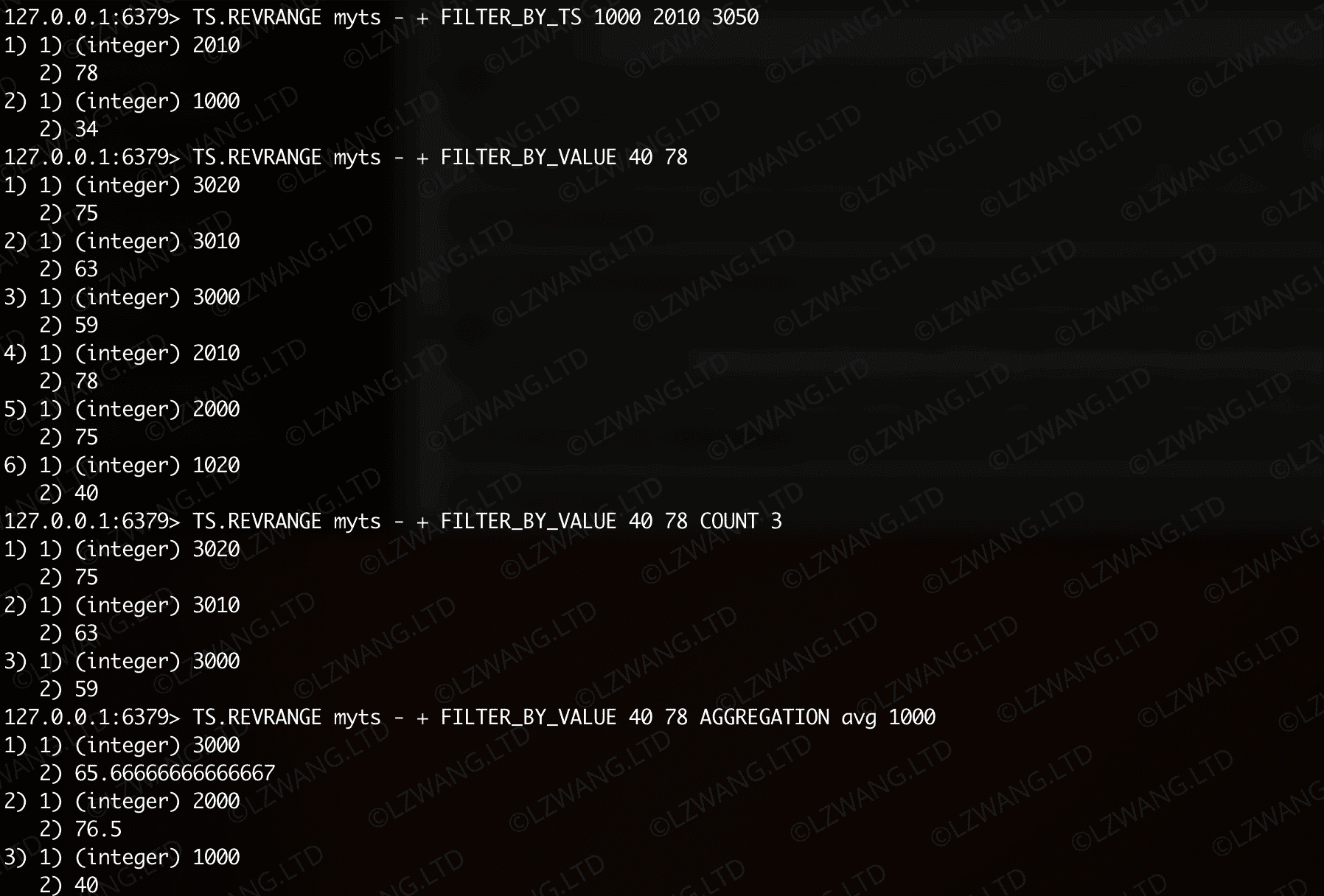
TS.REVRANGE 逆向查询一组样本数据
用法和复杂度与 TS.RANGE 一致,只是查询的结果是时间戳倒序
| Bash |
|---|
| TS.REVRANGE key fromTimestamp toTimestamp
[LATEST]
[FILTER_BY_TS TS...]
[FILTER_BY_VALUE min max]
[COUNT count]
[[ALIGN align] AGGREGATION aggregator bucketDuration [BUCKETTIMESTAMP bt] [EMPTY]]
|
| Bash |
|---|
| TS.CREATE myts
TS.MADD myts 1000 34 myts 1010 36 myts 1020 40
TS.MADD myts 2000 75 myts 2010 78 myts 2020 85
TS.MADD myts 3000 59 myts 3010 63 myts 3020 75
TS.REVRANGE myts - + FILTER_BY_TS 1000 2010 3050
TS.REVRANGE myts - + FILTER_BY_VALUE 40 78
TS.REVRANGE myts - + FILTER_BY_VALUE 40 78 COUNT 3
TS.REVRANGE myts - + FILTER_BY_VALUE 40 78 AGGREGATION avg 1000
TS.REVRANGE myts - + ALIGN 10 AGGREGATION min 20
TS.REVRANGE myts 5 + ALIGN - AGGREGATION min 20
TS.REVRANGE myts - 2015 ALIGN + AGGREGATION min 20
|
TS.MRANGE 正向查询一组跨多个TS的样本数据
查询多个符合条件的TS数据的样本数据,复杂度为 O(n/m+k)(同 TS.RANGE )
| Bash |
|---|
| TS.MRANGE fromTimestamp toTimestamp
[LATEST]
[FILTER_BY_TS ts...]
[FILTER_BY_VALUE min max]
[WITHLABELS | SELECTED_LABELS label...]
[COUNT count]
[[ALIGN align] AGGREGATION aggregator bucketDuration [BUCKETTIMESTAMP bt] [EMPTY]]
FILTER filter..
[GROUPBY label REDUCE reducer]
|
参数解释
- 此命令实质上综合了
TS.MGET (过滤TS数据) 和 TS.RANGE (过滤样本数据)两条命令,所以可以筛选出多组TS数据的多个符合条件的样本数据
GROUPBY label REDUCE reducer 参数用于将多个TS数据的结果进行再次回归分析(回归函数类型同AGGREGATION),顺序在AGGREGATION 之后
示例
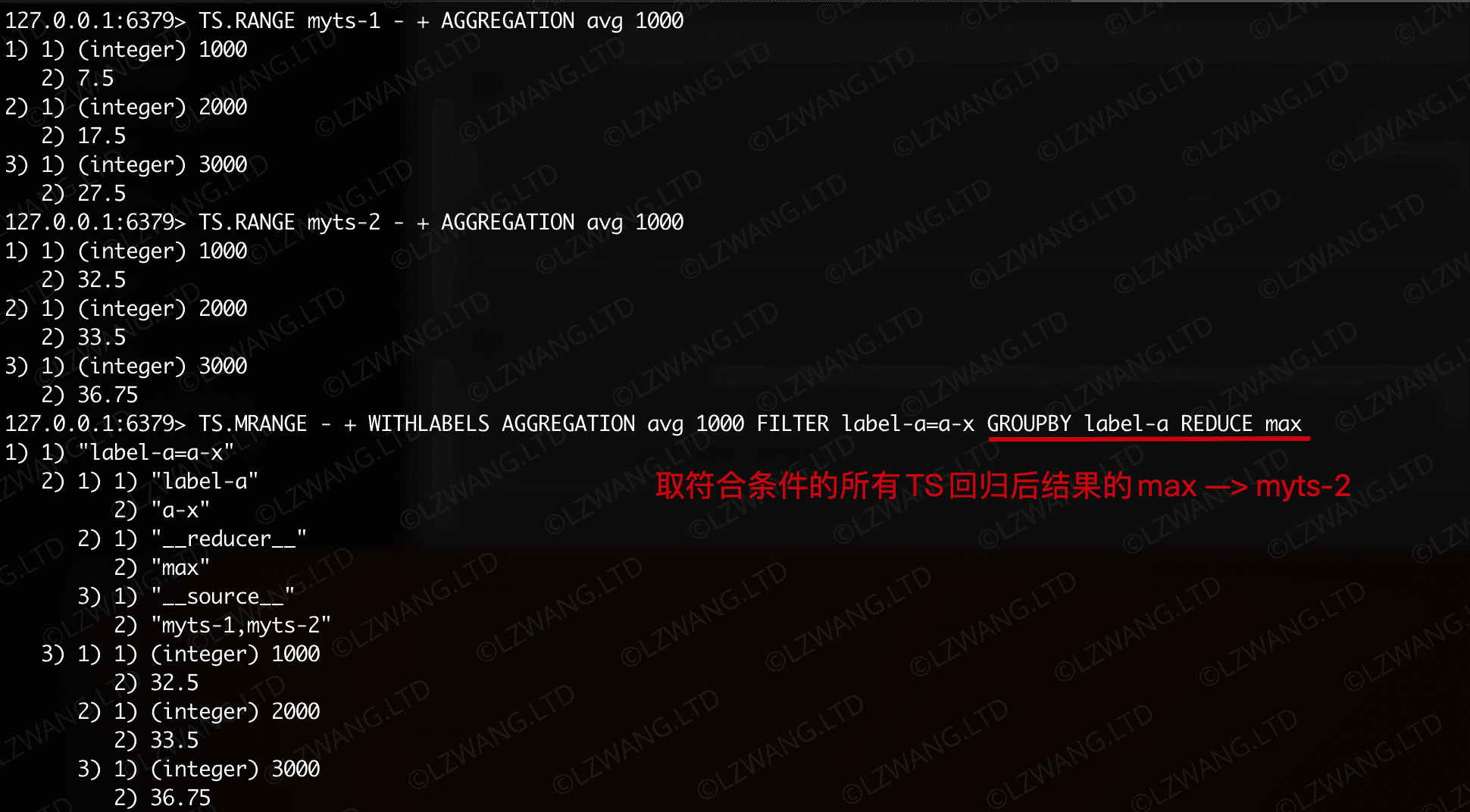
查询1,(1)以1000ms为回归周期做均值回归(2)TS数据的标签必须满足 label-a=a-x (3)对结果显示各TS数据的标签属性(4)对结果进行再聚合,对 label-a 标签的数据只取最大值结果作为最终结果
| Bash |
|---|
| TS.CREATE myts-1 LABELS label-a a-x label-b b-x
TS.CREATE myts-2 LABELS label-a a-x label-b b-y
TS.MADD myts-1 1000 2 myts-1 1010 4 myts-1 1020 8 myts-1 1030 16
TS.MADD myts-1 2000 12 myts-1 2010 14 myts-1 2020 18 myts-1 2030 26
TS.MADD myts-1 3000 22 myts-1 3010 24 myts-1 3020 28 myts-1 3030 36
TS.MADD myts-2 1005 5 myts-2 1015 25 myts-2 1025 45 myts-2 1035 55
TS.MADD myts-2 2005 6 myts-2 2015 26 myts-2 2025 46 myts-2 2035 56
TS.MADD myts-2 3005 7 myts-2 3015 36 myts-2 3025 47 myts-2 3035 57
TS.RANGE myts-1 - + AGGREGATION avg 1000
TS.RANGE myts-2 - + AGGREGATION avg 1000
TS.MRANGE - + WITHLABELS AGGREGATION avg 1000 FILTER label-a=a-x GROUPBY label-a REDUCE max
|
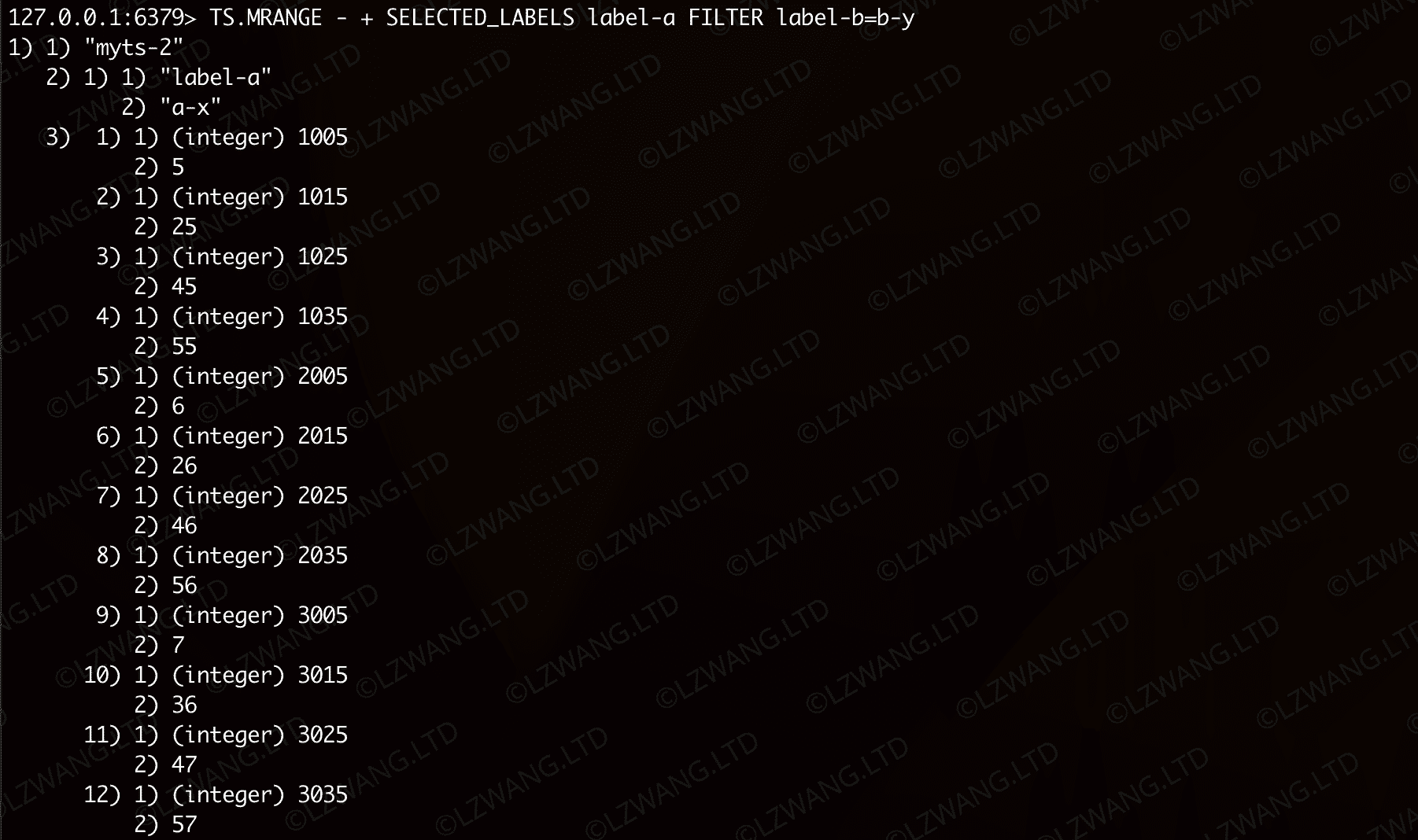
查询2,找到指定满足特定label的TS数据所有样本
| Bash |
|---|
| TS.MRANGE - + SELECTED_LABELS label-a FILTER label-b=b-y
|
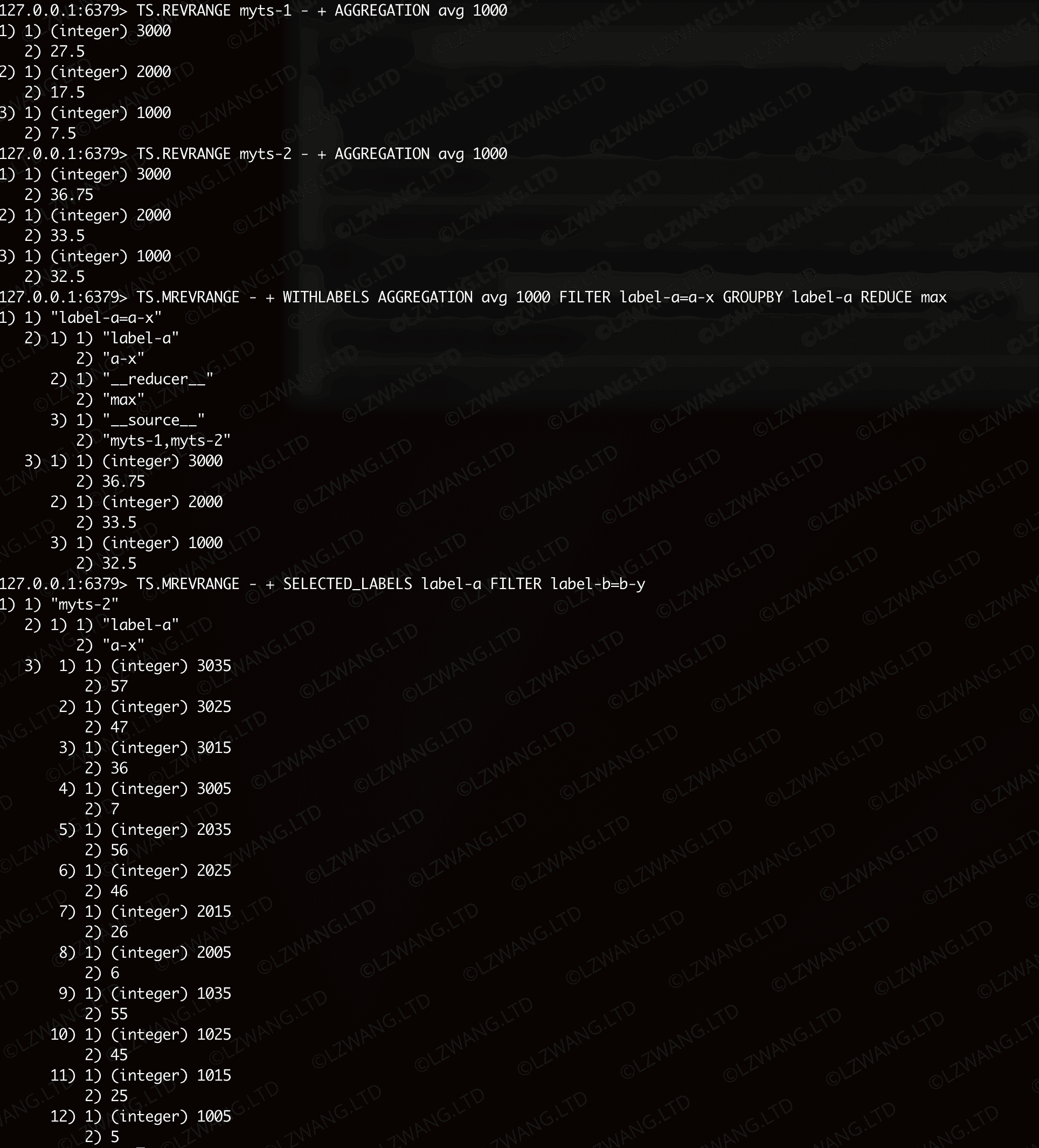
TS.MREVRANGE 逆向查询一组跨多个TS的样本数据
用法和复杂度与 TS.MRANGE 一致,只是查询的结果是时间戳倒序
| Bash |
|---|
| TS.MREVRANGE fromTimestamp toTimestamp
[LATEST]
[FILTER_BY_TS TS...]
[FILTER_BY_VALUE min max]
[WITHLABELS | SELECTED_LABELS label...]
[COUNT count]
[[ALIGN align] AGGREGATION aggregator bucketDuration [BUCKETTIMESTAMP bt] [EMPTY]]
FILTER filter..
[GROUPBY label REDUCE reducer]
|
| Bash |
|---|
| TS.CREATE myts-1 LABELS label-a a-x label-b b-x
TS.CREATE myts-2 LABELS label-a a-x label-b b-y
TS.MADD myts-1 1000 2 myts-1 1010 4 myts-1 1020 8 myts-1 1030 16
TS.MADD myts-1 2000 12 myts-1 2010 14 myts-1 2020 18 myts-1 2030 26
TS.MADD myts-1 3000 22 myts-1 3010 24 myts-1 3020 28 myts-1 3030 36
TS.MADD myts-2 1005 5 myts-2 1015 25 myts-2 1025 45 myts-2 1035 55
TS.MADD myts-2 2005 6 myts-2 2015 26 myts-2 2025 46 myts-2 2035 56
TS.MADD myts-2 3005 7 myts-2 3015 36 myts-2 3025 47 myts-2 3035 57
TS.REVRANGE myts-1 - + AGGREGATION avg 1000
TS.REVRANGE myts-2 - + AGGREGATION avg 1000
TS.MREVRANGE - + WITHLABELS AGGREGATION avg 1000 FILTER label-a=a-x GROUPBY label-a REDUCE max
TS.MREVRANGE - + SELECTED_LABELS label-a FILTER label-b=b-y
|
参考