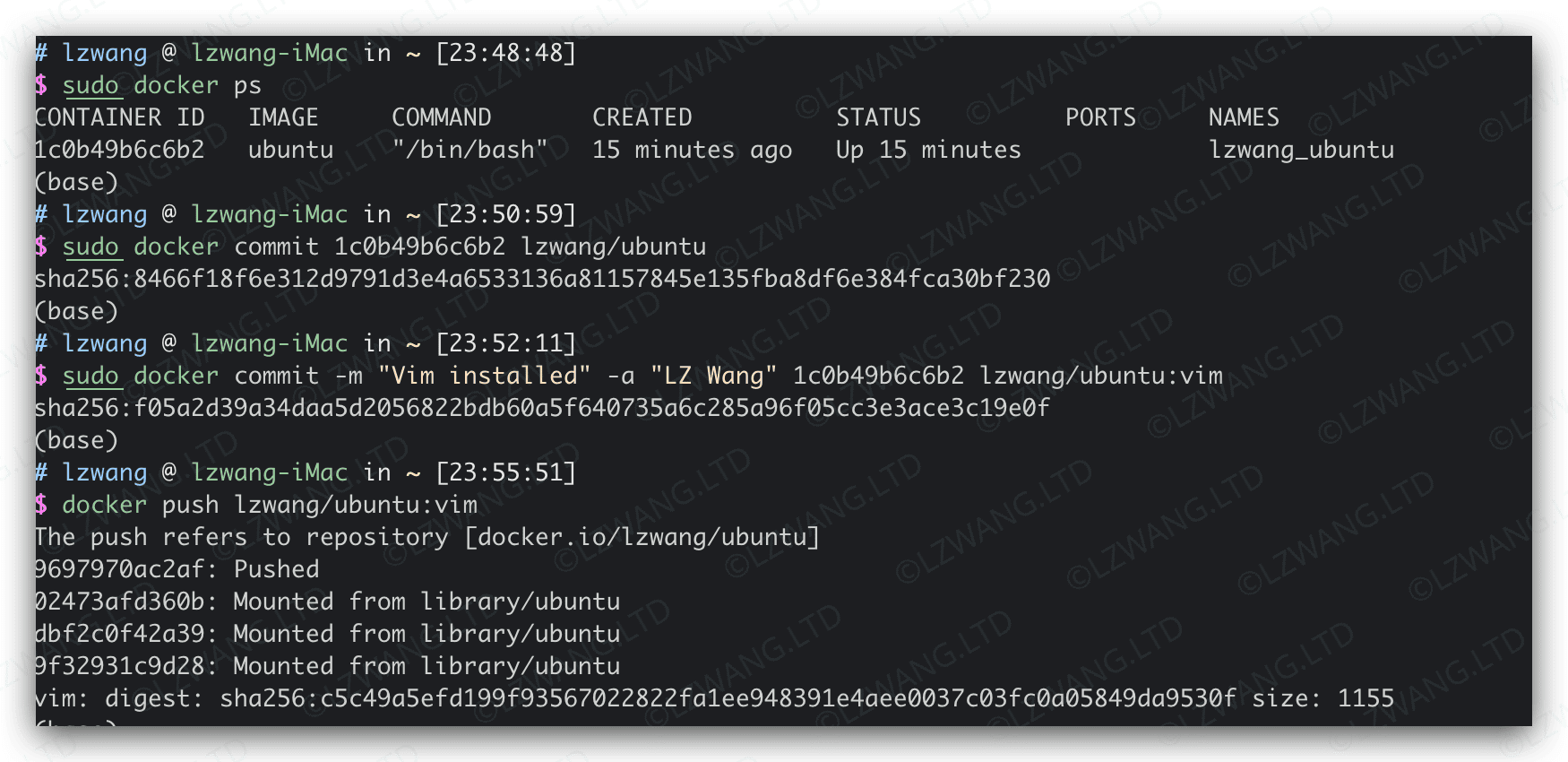
grep 正则表达式工具¶
概要: 在Linux和macOS使用正则表达式,高效匹配文本模式进行搜索
创建时间: 2022.12.20 21:49:08
更新时间: 2023.07.28 23:09:00
文本搜索工具grep¶
在Linux和Unix中,grep工具的全称是global regular expression print。在实际应用中,grep工具用于搜索文本文件中与指定正则表达式匹配的行,并将结果送到标准输出。grep接受的参数如下
| 参数 | 全称 | 意义 |
|---|---|---|
-i |
--ignore-case | 忽略大小写 |
-v |
--invert-match | 不匹配 |
-c |
--count | 输出匹配到项的数目 |
-l |
--files-with-matches | 输出匹配项文件名 |
-L |
--files-without-matches | 输出不包含匹配项的文件名 |
-n |
--line-number | 在每个匹配行前面加上该行在文件内的行号 |
-h |
--no-filename | 在同时搜索多个文件时,不输出文件名 |
创建playground进行测试搜索¶
创建若干文本文件用于测试¶
| Bash | |
|---|---|
简单的搜索测试¶
在所有以dirlist开头的txt文件中,搜索bzip字段
| Bash | |
|---|---|

输出包含
bzip字段的文件
| Bash | |
|---|---|
输出不包含
bzip字段的文件
| Bash | |
|---|---|
正则表达式中的元字符¶
RE中的元字符如下^, $, ., *, ?, \, |, -, +, [, ], {, }, (, )
其余字符均视为普通文字字符。
任意字符.¶
实例:在所有以dirlist开头的txt文件中,匹配所有包含zip的字符串(不输出文件名 -h)
| Bash | |
|---|---|
提示
上面示例匹配不到zip软件是因为它只包含3个字符,上述正则搜索至少4个字符。
锚(开头^ 结尾$)¶
实例:在所有以dirlist开头的txt文件中,搜索以zip开头和结尾的字符串。
匹配字符[ ]¶
特定位置字符匹配
匹配包含bzip或者gzip的字符串
| Bash | |
|---|---|
特定位置否定匹配
匹配包含
zip且不包含bzip或gzip的字符串
| Bash | |
|---|---|
字符范围匹配
匹配以大写字母开头的字符串
| Bash | |
|---|---|

匹配以字母或数字开头的字符串
| Bash | |
|---|---|
-的字符串
| Bash | |
|---|---|
参考下表:
| 字符串 | 描述 |
|---|---|
[:alpha:] |
字母,即[A-Za-z] |
[:lower:] |
小写字母,即[a-z] |
[:upper:] |
大写字母,即[A-Z] |
[:digit:] |
数字,即[0-9] |
[:alnum:] |
字母和数字,即[A-Za-z0-9] |
[:xdigit:] |
16进制数字,即[0-9A-Fa-f] |
[:blank:] |
空格和制表符 |
[:space:] |
空白字符,即ASCII的[\t, \r, \n, \v, \f] |
[:graph:] |
可见字符,即ASCII字符的 33~126 |
[:cntrl:] |
控制字符,即ASCII字符的 0~31 和127 |
[:pnuct:] |
标点符号,即ASCII的[ ,~,!,@,#,$,%,&,*,(,),-,_,=,+,[,],{,},\,\|,;,:,',",,,.,<,>,/,?`] |
[:print:] |
可打印字符,包括[:graph:]中的所有字符加上空格字符 |
扩展正则表达式¶
相比与基本正则表达式BRE,扩展正则表达式ERE与之仅仅是元字符的不同
| 正则表达式 | 元字符 |
|---|---|
| BRE | ^, $, ., *, ?, \\, \\|, -, +, [, ], {, }, (, ) |
| ERE | 除去BRE已有的外,还包括(, ), {, }, ?, +, \\|(对应各自功能) |
提示
在grep工具使用ERE时,需要加额外参数-E
或(|)¶
基本使用
| Bash | |
|---|---|
实例:匹配以
bz、gz或zip开头的字符串
| Bash | |
|---|---|
反例:如果不加
(),则意义是匹配以bz开头的或者包含gz和zip的字符串
| Bash | |
|---|---|
匹配元素零次或一次(?)¶
?代表其前面的元素是可选的,匹配0或1次。
实例:匹配电话号码
| Bash | |
|---|---|
提示
上面正则最后的$确保以数字结尾,没有多余字符

匹配元素零次或多次(*)¶
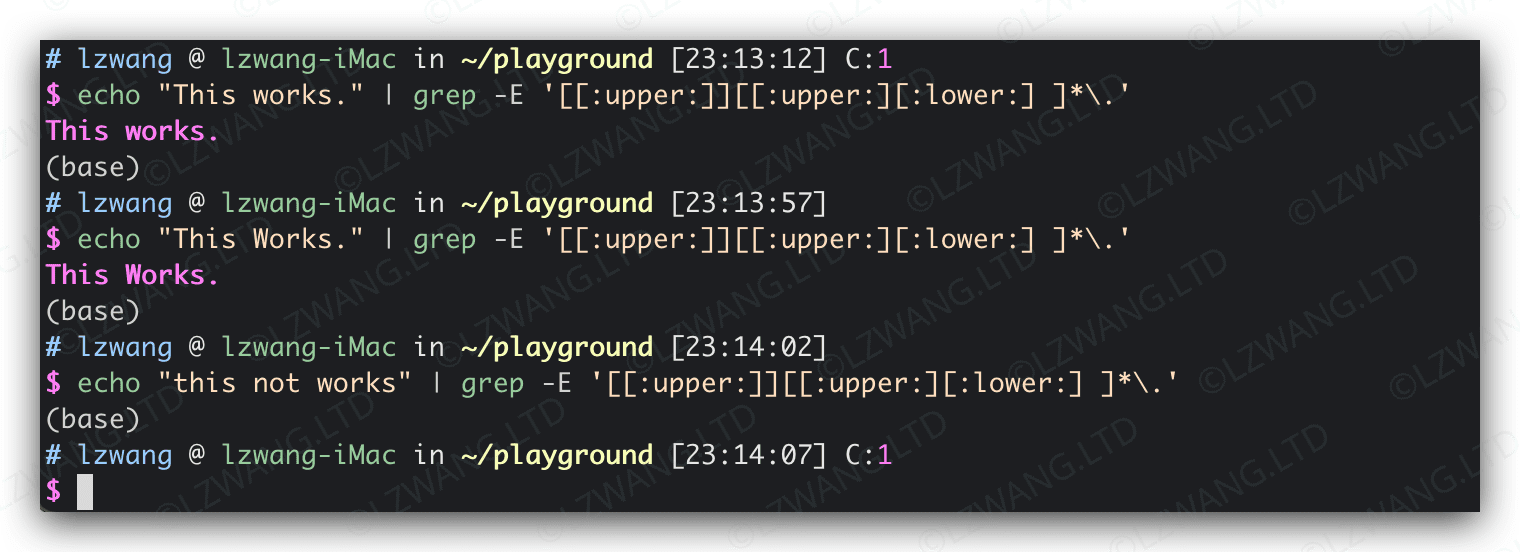
实例:匹配字符串是不是一句话(即是否以大写字母开头,句号结束,中间是任意数目的大小写字母和空格)
| Bash | |
|---|---|
匹配元素一次或多次(+)¶
与*类似,但要求前面的字符至少出现一次。
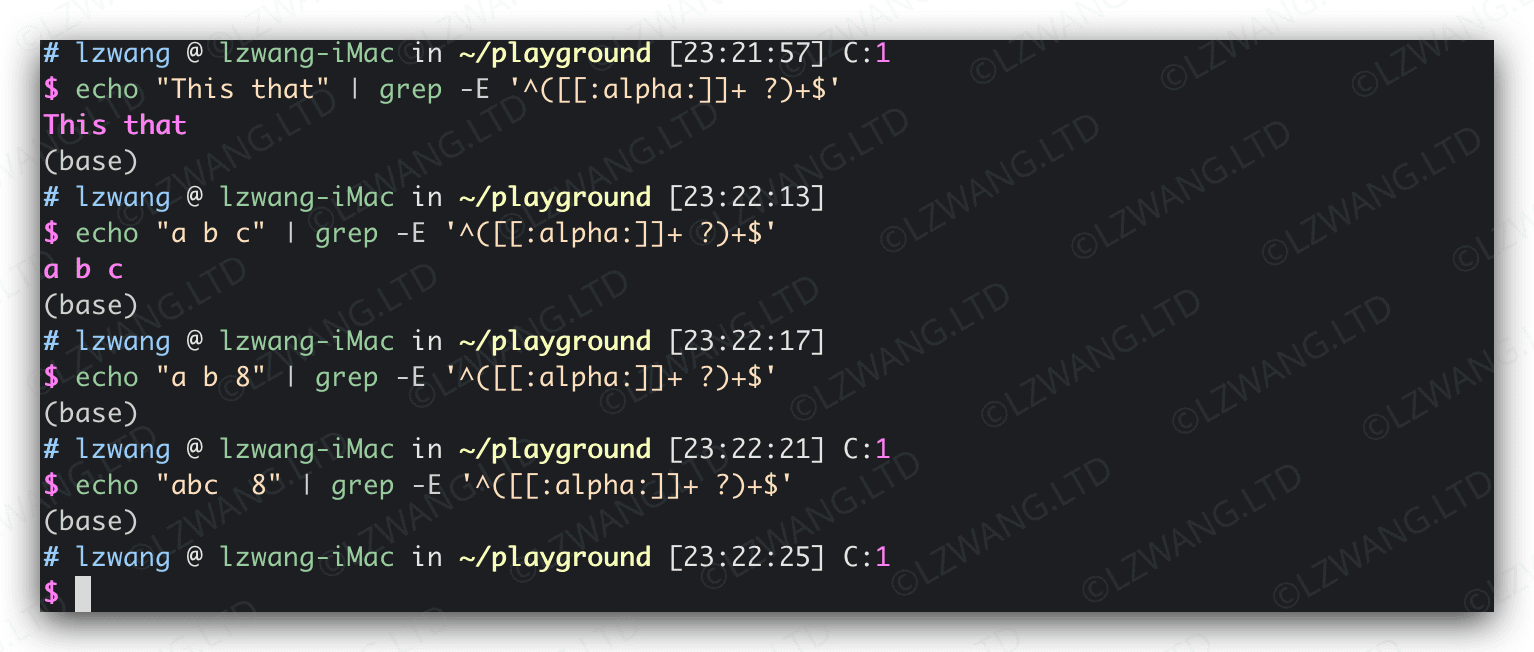
实例:匹配由单个空格分隔的一个或多个字母字符组成的字符串
| Bash | |
|---|---|
匹配元素指定次数({})¶
按次数匹配有如下几种使用方式:
{n}: 前面元素出现了n次{n,m}: 前面元素出现了n~m次{n,}: 前面元素出现了>n次{,m}: 前面元素出现了<=m次
实例:匹配电话号码(与4.2一样)
| Bash | |
|---|---|
